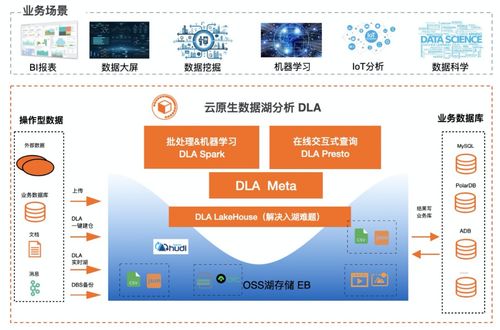
随着大数据技术的快速发展,数据湖已成为企业存储和处理海量数据的重要架构。对象存储OSS(Object Storage Service)以其高扩展性、低成本和可靠性,成为数据湖存储层的理想选择。数据湖分析在处理OSS中的数据时,常常面临性能瓶颈和成本挑战。本文探讨如何针对OSS优化数据湖分析的数据处理流程,提升效率并降低成本。
一、理解OSS特性与数据湖分析需求
对象存储OSS专为海量非结构化数据设计,提供高持久性和无限容量,但其数据访问延迟相对较高,且不支持传统文件系统的随机读写操作。数据湖分析通常涉及大规模数据的读取、转换和查询,如使用Apache Spark、Presto或AWS Athena等工具。优化目标是在OSS的存储经济性和数据处理性能之间找到平衡。
二、数据分区与组织策略优化
在OSS中存储数据时,合理的数据分区和组织是关键优化点。建议采用分层目录结构,例如按日期、地域或业务维度分区(如year=2023/month=10/day=01/)。这可以减少查询时的数据扫描量,提升分析工具的过滤效率。避免小文件问题:通过合并小文件或使用列式格式(如Parquet、ORC)来减少OSS的列表操作开销,从而降低延迟和成本。
三、选择合适的文件格式与压缩
针对OSS的数据读取优化,推荐使用列式存储格式(如Parquet或ORC),因为这些格式支持谓词下推和列裁剪,显著减少从OSS传输的数据量。结合压缩算法(如Snappy或Zstandard),可以进一步降低存储成本和网络带宽使用。注意,压缩比和读写性能需权衡:高压缩比可能增加CPU开销,但OSS的读取成本主要基于数据量,因此压缩通常有利。
四、利用缓存与索引机制
为了缓解OSS的高延迟问题,可以在数据湖架构中引入缓存层。例如,使用Alluxio或Redis作为热数据缓存,将频繁访问的数据暂存在高速存储中,减少直接OSS访问。对于查询密集型场景,构建元数据索引(如通过Apache Hudi或Delta Lake)可以加速数据定位,避免全表扫描。OSS本身不支持索引,但通过外部工具实现索引可以大幅提升分析性能。
五、并行处理与网络优化
数据湖分析工具(如Spark)通常采用分布式计算,优化并行读取策略至关重要。调整任务并行度,使其与OSS的分区数量匹配,避免过度分片导致的小文件问题。确保计算集群与OSS在同一区域(Region),以减少网络延迟和跨区域数据传输成本。对于大规模作业,使用OSS的传输加速功能或多部分上传机制,可以提升数据摄入效率。
六、监控与成本控制
优化不仅是性能提升,还包括成本管理。利用OSS的访问日志和监控工具(如阿里云SLS),分析数据访问模式,识别热点数据并调整存储策略(例如,将冷数据移至归档层)。设置生命周期策略,自动删除或迁移旧数据,降低存储费用。在数据处理流水线中,采用增量处理而非全量刷新,减少不必要的OSS读取操作。
七、案例与最佳实践
以某电商企业为例,其数据湖基于OSS存储用户日志,通过采用Parquet格式、按日分区,并利用Spark的动态分区修剪功能,查询性能提升了60%,同时存储成本降低30%。最佳实践包括:定期优化文件大小(目标100MB以上)、使用服务器端加密确保安全,并结合数据目录工具(如AWS Glue)维护元数据一致性。
总结,面向OSS优化数据湖分析需从数据组织、格式选择、缓存策略和成本监控等多维度入手。通过合理设计,企业可以充分发挥OSS的经济优势,同时确保数据分析的高效性。随着云原生技术的发展,未来可探索更多Serverless架构与OSS的集成,进一步简化优化流程。