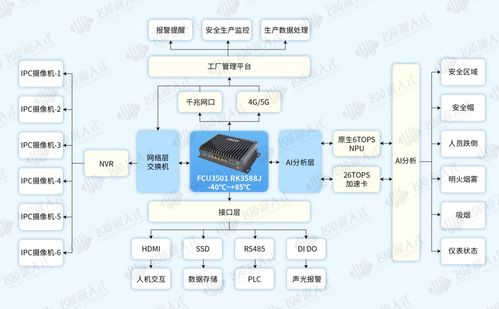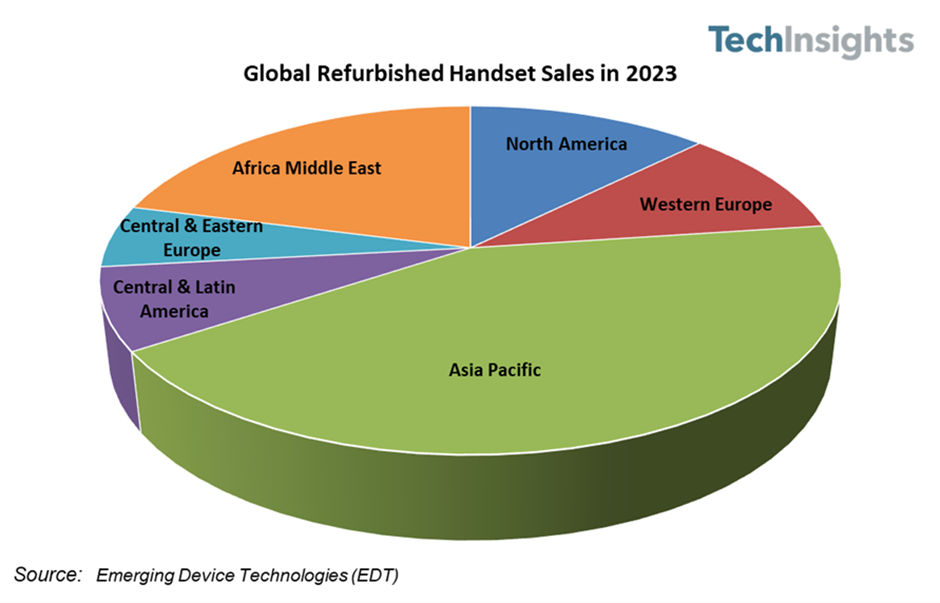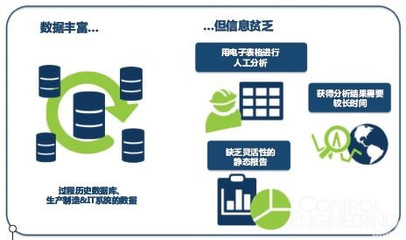
在当今数据驱动的决策环境中,过程数据——即记录系统、工作流或操作中连续事件的数据——已成为优化效率、预测维护和提升性能的关键。处理这种时序性、高频率且往往体量庞大的数据,需要专门的技术与工具。本文将系统性地介绍探索与分析过程数据的最佳工具链,涵盖从采集、存储、处理到可视化与分析的各个环节。
1. 数据采集与传输
过程数据的探索始于高效可靠的采集。工业物联网(IIoT)场景中,OPC UA(开放平台通信统一架构)是实时获取机器与传感器数据的行业标准协议,工具如KEPServerEX提供了强大的连接能力。对于日志流数据,Fluentd和Logstash是轻量级且灵活的收集引擎,能够统一来自多种源的数据并转发至下游。在云原生环境中,Apache Kafka作为分布式事件流平台,擅长处理高吞吐量的实时数据流,确保数据可靠传输,是构建实时流水线的核心。
2. 数据存储与管理
原始过程数据通常需要存储以供历史查询与回溯分析。时序数据库(TSDB)为此类数据量身定制,它们高效压缩存储时间戳-指标对。InfluxDB以其易用性和高性能查询著称,特别适合监控和物联网应用;Prometheus则与Kubernetes生态紧密集成,是云原生监控的事实标准。对于需要处理超大规模数据集或复杂分析的场景,Apache Druid能提供低延迟的查询,而ClickHouse则在分析型查询速度上表现卓越。若数据需与业务数据关联,现代数据湖如Delta Lake或Apache Iceberg atop对象存储(如AWS S3),提供了经济高效且支持ACID事务的存储方案。
3. 数据处理与计算
清洗、转换和聚合过程数据是提取价值的关键步骤。Apache Spark Structured Streaming和Apache Flink是处理流数据的顶级框架。Spark拥有丰富的生态系统和易用的API,适合批流一体处理;Flink则在事件时间处理、状态管理和低延迟方面更胜一筹,是实现复杂事件处理(CEP)的理想选择。对于更轻量或准实时的转换,Apache Kafka自身的Kafka Streams API允许在流数据上直接构建应用。在Python数据科学栈中,Pandas(用于批处理)和Streamz(用于流处理)也是探索性分析的得力助手。
4. 数据分析与建模
深入分析需要统计与机器学习工具。Python是这一领域的主导语言,其库生态无与伦比:NumPy/Pandas用于数据操作,SciPy用于科学计算,scikit-learn提供传统机器学习算法。对于深度学习或更复杂的模式识别(如异常检测),TensorFlow和PyTorch是首选。R语言在统计分析与可视化方面依然强大。值得注意的是,许多时序数据库(如InfluxDB)和可视化平台(见下文)已内置了基本的异常检测和预测功能,降低了分析门槛。
5. 数据可视化与监控
将过程数据转化为直观见解至关重要。Grafana是监控和可视化领域的明星,它支持多种数据源(尤其是时序数据库),能轻松创建丰富的仪表盘来实时展示指标、趋势和警报。对于更复杂的业务智能(BI)和交互式分析,Tableau、Power BI和Superset(开源)能够连接多种数据源,允许用户通过拖拽方式进行深度探索。在工业领域,SCADA系统和制造执行系统(MES)通常提供专用的过程可视化界面。
6. 端到端平台与云服务
为了简化管理,许多组织选择集成平台或云服务。公有云提供商(AWS, Azure, GCP)提供了从物联网核心到数据仓库、流处理及AI服务的全托管套件,例如AWS IoT Core + Kinesis + SageMaker。在开源领域,Apache IoTDB是一个集采集、存储、分析和可视化于一体的物联网原生时序数据管理系统。
选择工具的核心考量
选择最佳工具并非追求功能最全,而需综合考虑:
- 数据特性:体积、速度、多样性(是否为纯数值时序,或包含事件日志)。
- 延迟要求:是实时监控(亚秒级)、近实时分析(分钟级)还是批处理。
- 团队技能:现有技术栈与专业知识(如Java/Scala vs Python)。
- 成本与可扩展性:开源方案与商业软件、云服务的总拥有成本。
- 生态集成:工具是否能与现有系统平滑衔接。
###
探索过程数据是一个从数据管道到智能洞察的连贯旅程。最佳实践往往是组合使用上述工具,构建一个健壮、可扩展且高效的栈。例如,一个典型的现代架构可能采用Kafka进行数据流缓冲,Flink进行实时清洗与聚合,InfluxDB存储明细数据,Grafana进行可视化,并最终利用PySpark或云机器学习服务进行高级分析与模型部署。关键在于明确业务目标,从痛点出发,循序渐进地选择和集成最适合的工具,从而充分释放过程数据中蕴藏的宝贵价值。