在信息爆炸的时代,大数据已成为驱动社会进步与商业创新的关键引擎。海量、高速、多样且价值密度低的数据特性,对传统数据处理方式提出了前所未有的挑战。有效的数据处理,正是将原始数据转化为洞察与价值的核心枢纽。
大数据处理并非单一技术,而是一个融合了多层面技术与方法的系统工程。其核心目标在于实现数据的采集、存储、清洗、整合、分析与可视化,最终服务于决策支持、流程优化或智能应用。
核心技术架构
数据处理的技术栈通常构建在分布式计算框架之上。以Hadoop和Spark为代表的生态系统构成了坚实底座。Hadoop的HDFS提供了高容错性的分布式存储,MapReduce编程模型则开启了大规模并行批处理的先河。而Spark凭借其内存计算和DAG执行引擎,在迭代计算和流处理上表现更为出色,显著提升了处理速度。
对于实时性要求高的场景,流处理技术至关重要。Apache Flink、Apache Storm和Spark Streaming等框架,能够对持续不断的数据流进行毫秒级到秒级的处理与分析,广泛应用于实时监控、欺诈检测和个性化推荐等领域。
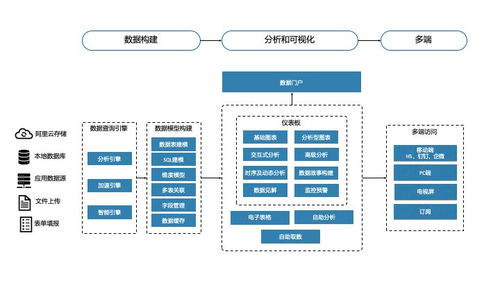
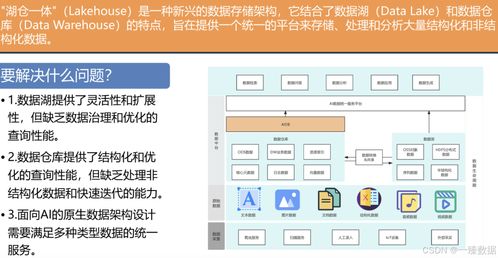
数据仓库与数据湖的构建是存储与管理环节的关键。传统数据仓库(如Teradata)结构严谨,适合稳定的商业智能分析;而数据湖(常基于HDFS或云对象存储构建)则以原始格式存储海量异构数据,提供了更高的灵活性和可扩展性,支持探索性分析和机器学习。
核心处理流程
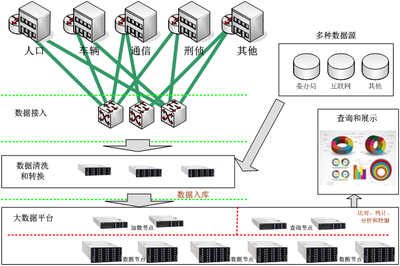
1. 数据采集与接入:从各类源头(数据库、日志、传感器、社交媒体等)通过ETL(提取、转换、加载)或更实时的ELT流程获取数据。工具如Apache Kafka常作为高吞吐的分布式消息队列,担当数据管道的角色。
2. 数据清洗与预处理:这是提升数据质量的决定性步骤。需要处理缺失值、异常值、重复记录,并进行格式标准化、数据归约等操作。这一过程往往耗费大量精力,但“垃圾进,垃圾出”的法则决定了后续所有分析的质量。
3. 数据存储与管理:根据数据的热度、结构和访问模式,选择分层存储策略(热数据、温数据、冷数据)。利用HBase、Cassandra等NoSQL数据库处理非结构化或半结构化数据,满足高并发读写需求。
4. 计算与分析:这是释放数据价值的核心。批处理用于历史数据的深度挖掘;流处理用于即时洞察;而图计算(如Apache Giraph)则擅长处理关系网络分析。机器学习与人工智能模型的训练与推理,正日益成为数据分析的高级形态。
5. 数据服务与可视化:将处理结果通过API、报表或交互式仪表板(如Tableau、Superset)呈现给最终用户或下游系统,形成数据驱动的决策闭环。
挑战与未来趋势
尽管技术不断进步,大数据处理仍面临诸多挑战:数据安全与隐私保护(如GDPR合规)、处理成本的优化、复杂数据(如音视频)的处理能力,以及对具备跨领域知识的复合型人才的迫切需求。
云原生数据处理已成为主流,Serverless架构让计算资源管理更加弹性与高效。数据处理与人工智能的融合(AI for Data, Data for AI)将更加紧密,自动化机器学习(AutoML)和增强分析正在降低数据洞察的门槛。联邦学习等隐私计算技术,为在保护隐私的前提下进行数据协作与价值挖掘提供了新路径。
大数据处理是一门平衡艺术,需要在性能、成本、复杂度与业务价值之间找到最佳契合点。唯有建立起健壮、高效且灵活的数据处理流水线,组织才能真正驾驭数据洪流,于数字浪潮中锚定方向,驶向智能化的未来。